Il team

Lars Løberg Monstad
Chief Executive Officer e co-fondatore
Lars è un esperto ingegnere di Machine Learning e sviluppatore Full-Stack specializzato nel music information retrieval. Ha pubblicato diversi articoli nel settore e sviluppato modelli IA avanzati per l'analisi e la trascrizione musicale. Come CEO e co-fondatore, guida la visione e la strategia di prodotto dell'azienda, combinando profonda competenza tecnica con leadership imprenditoriale.

Dr. Olivier Lartillot
Chief Science Officer e co-fondatore
Ricercatore di punta presso il Centro RITMO dell'UiO per gli studi interdisciplinari su ritmo, tempo e movimento e professore presso il MishMash Center for AI and Creativity. Ha ideato l'approccio ibrido transformer-regole che costituisce il nucleo della nostra tecnologia di trascrizione. Oltre 20 anni di esperienza nella musicologia computazionale e nel MIR (Music Information Retrieval).

Karstein Grønnesby
Direttore Operativo
Karstein ha conseguito un Master in Tecnologia Musicale presso l'Università di Oslo e vanta anni di esperienza nel coordinamento di progetti e produzioni nel settore musicale. Supervisiona la gestione dei progetti e guida il lato B2B del nostro prodotto, attingendo alla sua esperienza presso Samspill International Music Network e Norsk Viseforum. È anche il fondatore di Blåsemaker, un laboratorio dedicato alla costruzione di strumenti a fiato tradizionali norvegesi.
La nostra missione
Crediamo che la trascrizione musicale debba essere accessibile a tutti — dagli studenti che imparano le loro canzoni preferite ai musicisti professionisti che preservano le loro composizioni. La nostra tecnologia IA colma il divario tra audio e notazione, rendendo la creazione di spartiti semplice come registrare un'esecuzione.
Il nostro percorso
2022
Nasce l'idea
Nata dalla ricerca dell'Università di Oslo per risolvere un problema reale dei clienti.
UiO Growth House · 200k kr
2024
Finanziamento R&S
Qualificazione del Consiglio norvegese della ricerca.
Consiglio della ricerca · 500k kr
2025
Fondazione dell'azienda
Costituzione di Bots for Music AS.
Innovation Norway · 100k kr
2025
Costruiamo l'app
Estensione dell'app dalla R&S a nuove aree di mercato.
Sviluppata feb – dic 2025
Dic 2025
Lancio dell'app
La versione beta debutta con i nostri primi utenti.
Rilascio beta
Feb 2026
Primi ricavi
Primo cliente pagante, con preziosi feedback degli utenti.
Prima vendita
Mag 2026
Crescita
Forte crescita iniziale.
oltre 500 utenti
Supportato dal Consiglio Norvegese della Ricerca




La nostra ricerca
Bots for Music è nato dal progetto MUSCRIBE presso il centro RITMO di studi interdisciplinari su ritmo, tempo e movimento dell’Università di Oslo.
AMT-Augmentor
AMT-Augmentor è un toolkit Python per espandere i dataset di trascrizione musicale automatica (AMT) con trasformazioni audio di alta qualità — time-stretching, pitch-shifting, riverbero/filtraggio, rumore, gain/chorus — preservando l'allineamento audio-MIDI. È compatibile con MAESTRO, gestito da CLI e configurabile via YAML, con elaborazione parallela e validazione/suddivisione dei dataset integrata per accelerare l'addestramento di modelli AMT robusti. Open-source (MIT).
Vedi su GitHub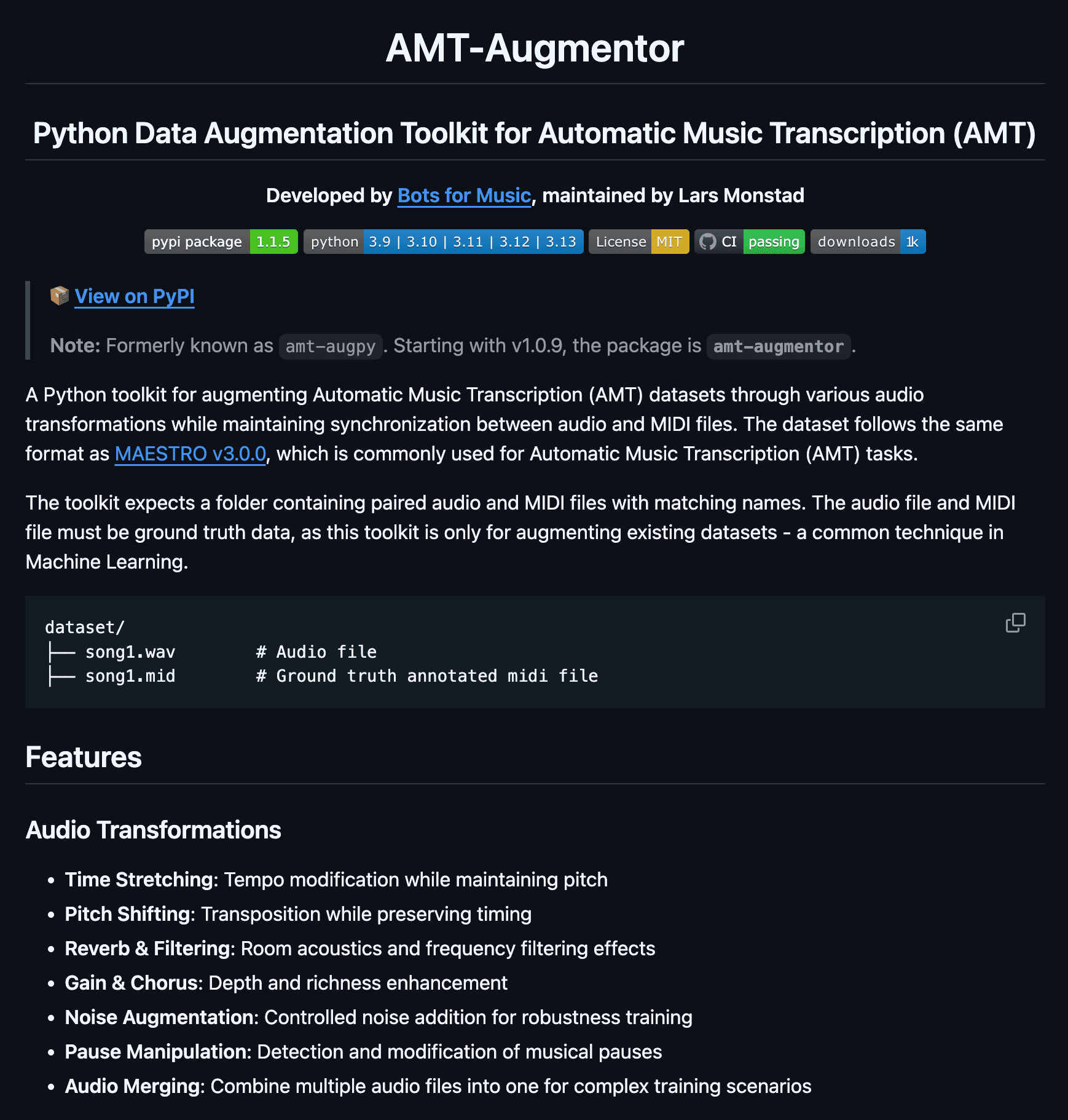

HF2: Dataset del Violino di Hardanger
Un dataset open accoppiato audio-MIDI di registrazioni di violino Hardanger norvegese, realizzato presso l'Università di Oslo per l'addestramento e la valutazione di modelli di trascrizione audio-MIDI. Estende il dataset originale HF1 a 119 coppie audio-MIDI distribuite su 39 brani unici (90.325 note annotate, ~970 MB) e introduce varianti emotive — ogni brano eseguito in cinque interpretazioni (originale, arrabbiato, allegro, triste, tenero) — insieme a una ground truth in CSV con dati di pitch ad alta precisione. Un dataset di ricerca per la comunità del music information retrieval.
Vedi su GitHubPubblicazioni recenti

ACM DLfM 2022
Segmentation, Transcription, Analysis and Visualisation of the Norwegian Folk Music Archive
Leggi l'articolo
TISMIR · ISMIR Transactions
A Dataset of Norwegian Hardanger Fiddle Recordings with Precise Annotation of Note and Beat Onsets
Leggi l'articolo
ISMIR 2023 · Late-Breaking Demo
Automatic Transcription of Multi-Instrumental Songs: Integrating Demixing, Harmonic Dilated Convolution, and Joint Beat Tracking
Vedi il posterIl nostro modello di ricerca in azione
Trascrizione dal vivo di musica per violino di Hardanger presso il MishMash Centre for AI and Creativity di Oslo · 08.04
Sulla stampa

Shifter · Notizie tech norvegesi